|
 |
 |
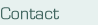 |
|
ProjectsMassively Parallel DNS of Flame Kernel Evolution in Spark-Ignited Turbulent MixturesParapyr - Direct Numerical Simulation of Turbulent Reactive FlowsEnergy conversion in numerous industrial power devices like automotive engines or gas turbines is still based on the combustion of fossil fuels. In most applications, the reactive system is turbulent and the reaction progress is influenced by turbulent fluctuations and mixing in the flow. The understanding and modeling of turbulent combustion is thus vital in the conception and optimization of these systems in order to achieve higher performance levels while decreasing the amount of pollutant emission. In the last several years, direct numerical simulations (DNS), i.e. the computation of time-dependent solutions of the compressible Navier-Stokes equations for reacting ideal gas mixtures, have been one of the most important tools to study fundamental issues in turbulent combustion. Due to the broad spectrum of length and time scales apparent in turbulent reactive flows, a very high resolution in space and time is needed to solve this system of equations. To be able to perform DNS of reactive flows including detailed chemical reaction mechanisms and a realistic description of molecular transport, it is necessary to make efficient use of High Performance Computing systems.
Induced ignition and the following evolution of premixed turbulent flames is a phenomenon of large practical importance as it occurs e.g. in Otto engine combustion. These processes have been studied in a model configuration of an initially uniform premixed gas under turbulent conditions which is ignited by an energy source in a small region at the center of the computational domain. Figure 1 shows the spatial distribution of vorticity and that of the OH radical in one such turbulent flame kernel about 1 ms after the ignition. Performance on the NEC SX-8 systemThe algorithms in the PARAPYR code allow for a highly efficient exploitation of the compute power of the SX-8 architecture. On one CPU the code achieves around 9 GFLOP/s which is 56% of the peak performance. Also the scaling behavior is quite impressive. Figure 2 show the performance and turn around times for computations on 24, 32, 36 and 72 nodes. The grid sizes were chosen such that the number of grid points scales with the number of CPUs. On the full machine with 576 CPUs, a performance of 4.4 TFLOP/s (48% of peak) was measured.
|
|